Chatbots bieten seit ChatGPT die Möglichkeit sich in natürlicher Sprache mit einem System auszutauschen, das über ein sehr umfangreiches Wissen verfügt. Mit der zunehmenden Verbreitung der Tools sind auch immer mehr Menschen mit diesen Werkzeugen vertraut und gewohnt diese zu nutzen. Daher bietet es sich an, diese Kontaktmöglichkeit auch zu nutzen insbesondere dort, wo sie für die Nutzenden als die Anbietenden Vorteile versprechen.
Während die Sprachmodelle wie ChatGPT nur allgemeine Auskunft geben können, suchen Unternehmen und Organisationen auch nach Lösungen eigene Dokumente und Wissensquellen über einen Chatbot in natürlicher Sprache Ihren Kunden, Mitarbeitenden zur Verfügung zu stellen.
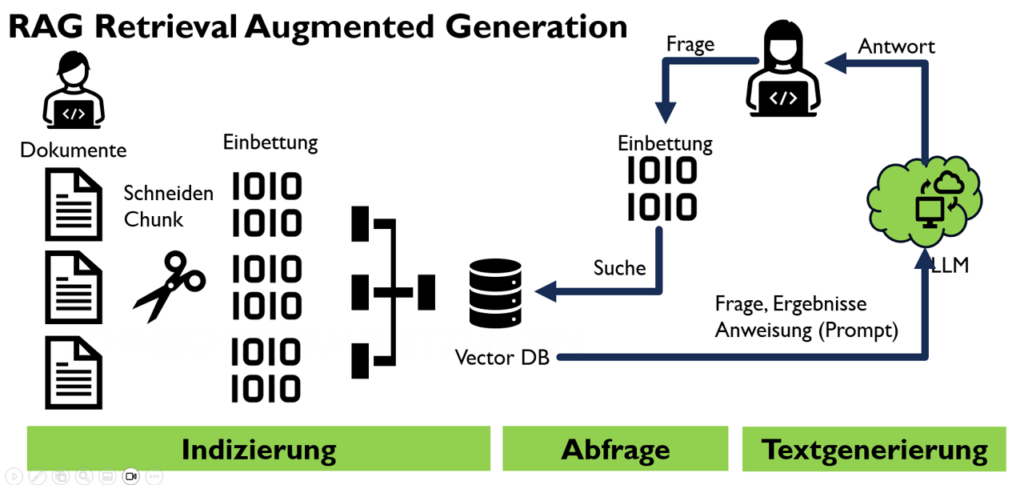
Hier kommt eine Technologie zum Tragen, die RAG (Retrieval-Augmented Generation) genannt wird. Eine Technologie zur Kombination aus Datenbankabfragen und Textgenerierung durch Sprachmodelle (LLM). Damit kann ein Chatbot mit der Fähigkeit eines LLMs auf Fragen anhand von bereitgestellten Daten suchen und antworten.
Alternativ kann ein LLM auch mit eigenen Daten „antrainiert“ (fine tuning) werden. In diesem Blog möchte ich aber auf das RAG Verfahren eingehen, da es erheblich einfacher zu bewerkstelligen ist, weniger Rechenpower benötigt und zuverlässiger gestaltet werden kann.
Bei RAG handelt es sich um einen einfachen dreistufigen Prozess: Indizierung der Daten, Abfrage der gesuchte Information und Generierung einer Textantwort.
Indizierung
Der Indizierungsprozess bereitet die Daten für den Abfrageprozess vor. Hier wird alles gesammelt, was das LLM wissen soll, zum Beispiel Unternehmensleitlinien für Mitarbeiter, Verfahrens- und Prozessdokumentationen, Produktdokumentation, Unternehmenswebsite usw., je nachdem, was der Chatbot beantworten soll. Hierbei spielt es eine große Rolle vorher zu definieren, welchen Usecase der Chatbot abdecken soll, wer die Stakeholder und Nutzenden sind mit welcher Zielsetzung.
Dann werden die Dokumente kleinere Textstücke geschnitten (Chunks) (damit die Stücke leicht in die Kontextgröße des LLM passen können). Anschließend werden die Textstücke mit einem Einbettungsmodell in Vektorrepräsentationen umgewandelt (damit später ähnliche Stücke leicht gefunden werden). Diese Text-Einbettungspaare werden in einem Index oder Vektordatenbank für die spätere Verwendung gespeichert.
Abfrageprozess
Im Abfrageprozess wird die Frage des Benutzenden an den Chatbot gestellt. Diese wird mit demselben Einbettungsmodell kodieren und dann wird eine Ähnlichkeitssuche durchgeführt, um die ähnlichsten (und meistens relevantesten) Textstücke in der (Vector-) Datenbank zu finden.
Textgenerierung
Dann werden für die Generierung des Antworttexts die Textstücke in eine Aufforderung gepackt, die auch die ursprüngliche Frage der Fragenden enthält. Das LLM erzeugt dann eine Antwort, mit den in den abgerufenen Textstücken bereitgestellten Informationen.
Einsatzgebiete
Die Lösung kann als Wissen-Chatbot, FAQ-Chatbot, KI gestützter Servicedesk dienen oder beim Wissenmanagement unterstützen. Bis zu einem gewissen Grad kann es auch eine alternative zur klassischen Suche nach Dokumenten und Wissen dienen. Insbesondere wenn die Suchbegriffe (Keywords) nicht so präzise formuliert werden können.
- Kundenservice, Infodesk und First-Level Service bzw. noch dem First-Level Service vorgelagert.
- Unterstützung von Interessenten bei der Informationssuche auf der eigenen Website.
- Hilfestellung zu Lernhinhalten beim E-Learning und Schulungen.
- Informationssuche wie z.B. Regelungen im Unternehmen, Produktinformationen usw.
- Unterstützung von Arbeitsabläufen, um aufkommende Fragen zu beantworten.
Tools und Lösungen
RAG ist mittlerweile ein anerkannter Prozess und wird in unterschiedlichen Formen umgesetzt. Vorbereitet sind die Werkzeuge von LlamaIndex und LangChain. OpenAI selbst verbirgt diesen Prozess auch in seiner benutzerdefinierten GPT- und Assistentenfunktion, wenn eigene Dokumente hochgeladen werden. Hinzu kommen die Vektordatenbanken wie Pinecone und Chroma die die Speicherung der Daten und anschließend den Abruf unterstützen.
Mittels LlamaIndex oder LangChain, ChromaDB als Vectordatenbank und z.B. Mistal als LLM sowie einer Chatbot UI kann ein RAG als Open Source Modell auch lokal aufgebaut und betrieben werden.
Ein sehr einfacher und schnell umsetzbare Weg ist es ein RAG mittels Microsoft Copilot Studio zu realisieren. Natürlich gibt es in der Azure-Plattform Möglichkeiten ein RAG abzubilden mit dem Azure Chatbot Tool. Hier wird die Indizierung und Embedding durch Azure AI Search realisiert.
Der Vollständigkeit halber möchte ich noch Microsoft 365 Copilot erwähnen, mit der unter Nutzung der Graphen eine vergleichbare Lösung bietet, mit der Fragen zu internen Dokumenten textgeneriert beantwortet werden können.
Bei den Werkzeugen gibt es bereits eine große Auswahl und unterschiedliche Lösungsansätze. Hier hängt die richtige Wahl der Werkzeuge von der Anforderung und den Rahmenbedingungen ab. Kosten, Datenschutz, Vertraulichkeit, Flexibilität, Lizenzen, Quantität, Qualität, Komplexität usw.
Die Möglichkeiten reichen von der einfachen Buchung einer gehosteten Chatbot Lösung oder als GPT in OpenAI bzw. Microsoft Copilot Studio bis hin zu individuellen und komplexen Lösungen in Azure AI oder Eigenbau mit Open Source Komponenten.
Getestet habe ich sowohl die Microsoft Copilot Studio als auch Open Source Lösungen u.a. mit Olama Mistral, Langchain, ChromaDB und Stramlit. Die Umsetzung mit Microsoft Copilot Studio ist einfach und schnell einzurichten und auch leistungsfähig. Allerdings sind bis auf die Optimierung der Datenquellen keine Anpassungen möglich. Die Open Source Lösung ist dagegen komplexer einzurichten, läuft auf Wunsch vollständig lokal auf einem Notebook (am besten mit GPU) und ist flexibler zu konfigurieren. Das hat mir auch geholfen die RAG Technologie besser zu verstehen und hinter die Kulissen zu schauen.
Herausforderungen
Dieser RAG-Prozess ist grundsätzlich einfach und effektiv, aber in der Praxis sind oft einige Herausforderungen zu meistern:
- Datenschutz oder Vertraulichkeit. Wie und wo wird die Lösung betrieben, über welche Server oder Dienste laufen die Prozesse?
- Aufbereitung der Dokumente und Daten die in den RAG-Prozess gegeben werden. Einfach das gesamte „Wissen“ an Dokumenten, Intranetseiten usw. einkippen wird zu keinen guten Ergebnissen führen.
- Feintuning hinsichtlich der Indizierung und des Zuschneidens der Informationen und der dazugehörigen Überlappung
- RAG kann die relevantesten Informationsstücke nicht für die Generierung abrufen. Wenn ein ähnliches, aber irrelevantes Stück abgerufen wird, gibt der LLM falsche Antworten auf die ursprüngliche Abfrage des Benutzers.
- Die von RAG abgerufenen Stücke haben nicht den richtigen Kontext. Manchmal fehlen den abgerufenen Stücken die umgebenden Kontexte, was sie nutzlos für die Generierung nützlicher Antworten macht oder sogar widersprüchliche Informationen für den LLM bereitstellt.
- Verschiedene Fälle von Benutzerabfragen erfordern unterschiedliche Abfrage- oder Generierungsstrategien.
- Richtige „Temperatur“ des LLMs und der Anweisung (Prompt) an das LLM bei der Generierung des Antworttextes
- Die Datenstruktur ist möglicherweise nicht für eine Ähnlichkeitssuche mit Einbettungen geeignet.
Möglichkeiten der Optimierung
Grundprozess RAG: Der RAG-Grundprozess umfasst die Indexierung, der Abfrage und die Generierung von Daten. Die Indexierung beinhaltet die Vorbereitung der Datenbank durch das Speichern und Organisieren der Informationen für den späteren Zugriff. Die Abfrage ist der Prozess, bei dem relevante Daten aus der Datenbank abgerufen werden, um eine Anfrage zu beantworten. Die Generierung ist der letzte Schritt, bei dem die abgerufenen Informationen verwendet werden, um eine Antwort oder eine Ausgabe zu generieren.
- Techniken vor der Indizierung: Bevor die Einbettung erfolgt, können verschiedene Techniken angewendet werden, um die Qualität der indexierten Daten zu verbessern. Dazu gehören Maßnahmen wie die Entfernung irrelevanter Informationen, die Umstrukturierung der Daten für eine bessere Verarbeitung und die Hinzufügung von Metadaten für effizienteren Zugriff. Die Abschnittsoptimierung beinhaltet die Festlegung der optimalen Länge und der Überlappung (overlap) für die abgerufenen Abschnitte. Es ist naheliegend, dass eine gute Datenqualität auch zu besseren Ergebnissen führt.
- Abfragetechniken: Nachdem die Daten indexiert sind, gibt es verschiedene Techniken, um die Effektivität der Abfrage zu verbessern. Dazu gehört die Verwendung alternativer Suchmethoden wie Volltextsuche oder strukturierte Abfragen, um die Genauigkeit der Ergebnisse zu erhöhen. Die Verwendung verschiedener Einbettungsmodelle ermöglicht es, verschiedene semantische Informationen einzufangen und für spezifische Aufgaben anzupassen. Zusätzlich können spezielle Methoden wie rekursiver oder kontextbewusster Abfrage sowie hierarchischer Abfrage angewendet werden, um präzisere und relevantere Ergebnisse zu erzielen. Ebenso eine Kombination verschiedener Verfahren die anschließend mithilfe eines LLMs zusammengefasst werden.
- Techniken nach der Abfrage: Nachdem relevante Daten abgefragt wurden, können weitere Techniken angewendet werden, um die Qualität der Ergebnisse zu verbessern. Dies kann durch Ordnen oder Bewerten der abgefragten Abschnitte geschehen, um die relevantesten Informationen zu priorisieren. Die Informationskompression beinhaltet die Zusammenfassung oder Extraktion von Schlüsselinformationen aus den abgefragten Daten, um die Generierung effizienter zu gestalten und Rauschen zu reduzieren.
- Ausgewogenheit von Qualität und Latenz: Schließlich ist es wichtig, einen Ausgleich zwischen Qualität und Latenz zu finden, um eine effiziente RAG-Pipeline zu gewährleisten. Dies kann erreicht werden, indem kleinere, schnellere LL-Modelle für bestimmte Schritte verwendet werden, um die Latenzzeiten zu minimieren. Das parallele Ausführen von Zwischenschritten kann den Gesamtprozess beschleunigen, während die Implementierung von Caching häufig gestellte Fragen oder Abfragen speichert, um die Antwortzeit zu verbessern. Darüber hinaus kann das LLM mehrere Entscheidungen treffen, um die Effizienz des Gesamtprozesses zu steigern und gleichzeitig eine hohe Qualität der Ergebnisse sicherzustellen.
Schlussfolgerung
RAG wird zukünftig fester Bestandteil im Wissensmanagement und im Zugang zu Informationen spielen. So wie es Suchfunktionen in Dokumenten oder Suchmaschinen im Unternehmen oder im Internet sind. Suchmaschinen werden sich auch zunehmen in die Richtung entwickeln und die Funktionen in vielen Anwendungen die mit Daten, Dokumenten und Texten agieren zu finden sein.
Dabei muss es nicht unbedingt ein klassischer Chatbot sein, es kann ein Copilot sein oder einfach eine Hilfefunktion so wie ein Index oder eine Suchfunktion. In Gestalt eines Chatbots können noch weitere Funktionen und Fähigkeiten integriert werden, die mit dem ohnehin notwendigen LLM direkt genutzt werden können (Prompten).
Wenn Sie Fragen rund um RAGs haben oder planen einen solche Lösung einzuführen kommen Sie gerne auf mich zu. Anhand einer Checkliste können wir auch die geeignete Lösung auswählen und eine Umsetzung planen.